
A Big Four accounting firm with offices in Tokyo recently asked Catalyst to demonstrate the effectiveness of Insight Predict, technology assisted review (TAR) based on continuous active learning (CAL), on a Japanese language investigation. They gave us a test population of about 5,000 documents which had already been tagged for relevance. In fact, they only found 55 relevant documents during their linear review.
We offered to run a free simulation designed to show how quickly Predict would have found those same relevant documents. The simulation would be blind (Predict would not know how the documents were tagged until it presented its ranked list.) That way we could simulate an actual Predict review using CAL.
We structured a simulated Predict review to be as realistic as possible, looking at the investigation from every conceivable angle. The results were outstanding; we couldn’t believe what we saw. So, we ran it again, using a different starting seed. And again. And again. In fact, we did 57 different simulations starting with relevant seeds (singularly with each relevant document). A non-relevant seed. And a synthetic seed.
Regardless of the starting point, Predict was able to locate 100% of the relevant documents after reviewing only a fraction of the collection. You won’t believe your eyes either.
Complicating Factors
Everything about this investigation would normally be challenging for a TAR project.
To begin with, the entire collection was in Japanese. Like other Asian languages, Japanese documents require special attention for proper indexing, which is the first step in feature extraction for a technology assisted review. At Catalyst, we incorporate semantic tokenization of the CJK languages directly into our indexing and feature extraction process. The value of that approach for a TAR project cannot be overstated.
To complicate matters further, the collection itself was relatively small, and sparse. There were only 4,662 coded documents in the collection and, of those, only 55 total documents were considered responsive to the investigation. That puts overall richness at only 1.2%.
The following example illustrates why richness and collection size together compound the difficulty of a project. Imagine a collection of 100,000 documents that is 10% rich. That means that there are 10,000 responsive documents. That’s a large enough set that a machine learning-based TAR engine will likely do a good job finding most of those 10,000 documents.
Next, imagine another collection of one million documents that is 1% rich. That means that there are also 10,000 responsive documents. That is still a sizeable enough set of responsive documents to be able to train and use TAR machinery, even though richness is only 1%.
Now, however, imagine a collection of only 100 documents that is 1% rich. That means that only 1 document is responsive. Which means that either you’ve found it, or you haven’t. There are no other responsive documents other than that document itself, so there are no other documents that, through training of a machine learning algorithm, can lead you to the one responsive document. So a 1% rich million document collection is a very different creature than a 1% rich 100 document collection. These are extreme examples, but they illustrate the point that small collections are difficult and low richness collections are difficult, but small, low richness collections are extremely difficult.
Small collections like these are nearly impossible for traditional TAR systems because it is difficult to find seed documents for training. In contrast, Predict can start the training with the very first coded document. This means that Predict can quickly locate and prioritize responsive documents for review, even in small document sets with low richness.
Compounding these constraints, nearly 20% (10 out of 55) of the responsive documents were hard copy Japanese documents that had to be OCR’d. As a general matter, it can be somewhat difficult to effectively OCR Japanese script because of the size of the character set, the complexity of individual characters, and the similarities between the Kanji character structures. Poor OCR will impair feature extraction which will, in turn, diminish the value of a document for training purposes, making it much more difficult to find responsive documents, let alone find them all.
Simulation Protocol
To test Predict, we implemented a fairly standard simulation protocol—one that we used for NIST’s TREC program and often use to let prospective clients see how well Predict might work on their own projects. After making the text of the documents available to be ingested into Predict, we simulate a Predict prioritized review using the existing coding judgments in a just in time manner, and we prepare a gain curve to show how quickly responsive documents are located.
Since this collection was already loaded into our discovery platform, Insight Discovery, we had everything we needed to get the simulation underway: document identification numbers (Bates numbers); extracted text and images for the OCR’d documents; and responsiveness judgments. Otherwise, the client simply could have provided that same information in a load file.
With the data loaded, we simulated different Predict reviews of the entire collection to see how quickly responsive documents would be located using different starting seeds. To be sure, we didn‘t need to do this just to convince the client that Predict is effective; we wanted to do our own little scientific experimentation as well.
Here is how the simulation worked:
- In each experiment, we began by choosing a single seed document to initiate the Predict ranking, to which we applied the client’s responsiveness judgment. We then ranked the documents based on that single seed.[1]
- Once the initial ranking was complete, we selected the top twenty documents for coding in ranked order (with their actual relevance judgments hidden from Predict).[2]
- We next applied the proper responsiveness judgments to those twenty documents to simulate the review of a batch of documents, and then we submitted all of those coded documents to initiate another Predict ranking.
We continued this process until we had found all the responsive documents in the course of each review.
First Simulation
We used a relevant document to start the CAL process for our first simulation. In this case, we selected a relevant document randomly to be used as a starting seed. We then let Predict rank the remaining documents based on the initial seed and present the 20 highest-ranked documents for review. We gave Predict the tagged values (relevant or not) for these documents and ran a second ranking (now based on 21 seeds). We continued the process until we ran out of documents.
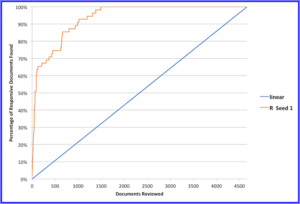
Figure 1
As is our practice, we used a gain curve to uniformly evaluate the results of the simulated reviews. A gain curve is helpful because it allows you to easily visualize the effectiveness of every review. On the horizontal x-axis, we plot the number of documents reviewed at every point in the simulation. On the vertical y-axis, we plot the number of documents coded as responsive at each of those points. The faster the gain curve rises, the better, because that means you are finding more responsive documents more quickly, and with less review effort.
The linear line across the diagonal shows how a linear review would work, with the review team finding 50% of the relevant documents after reviewing 50% of the total document population and 100% after reviewing 100% of the total.
The red line in Figure 1 shows the results of the first simulation, using the single initial random seed as a starting point (compared to the black line, representing linear review). Predict quickly prioritized 33 responsive documents, achieving a 60% recall upon review of only 92 documents.
While Predict efficiency diminished somewhat as the responsive population was depleted, and the relative proportion of OCR documents was increasing, Predict was able to prioritize fully 100% of the responsive documents within the first 1,491 documents reviewed (32% of the entire collection). That represents a savings of 68% of the time and effort that would have been required for a linear review.
Second Test
The results from the first random seed looked so good that we decided to try a second random seed, to make sure it wasn’t pure happenstance. Those results were just as good.
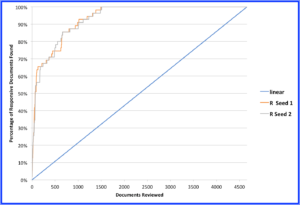
Figure 2
In Figure 2, the gray line reflects the results of the second simulation, starting with the second random seed. The Predict results were virtually indistinguishable through 55% recall, but were slightly less efficient at 60% recall (requiring the review of 168 documents). The overall Predict efficiency recovered almost completely, however, prioritizing 100% of the responsive documents within the first 1,507 documents (32.3%) reviewed in the collection—a savings again of nearly 68% compared with linear review.
Third Simulation
The results from the first and second runs were so good that we decided to continue experimenting. In the next round we wanted to see what would happen if we used a lower-ranked (more difficult for the algorithm to find) seed to start the process. To accomplish that, we chose the lowest-ranked relevant document found by Predict in the first two rounds as a starting seed. This turned out to be an OCR’d document (which was likely the most unique responsive document) to initiate the ranking. To our surprise, Predict was just about as effective starting with this lowly-ranked seed as it had been before. Take a look and see for yourself.[3]
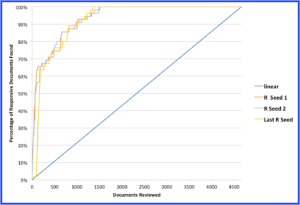
Figure 3
The yellow line in Figure 3 shows what happened when we started with the last document located during the first two simulations. The impact of starting with a document that, while responsive, differs significantly from most other responsive documents is obvious. After reviewing the first 72 documents prioritized by Predict, only one responsive document had been found. However, the ability of Predict to quickly recover efficiency when pockets of responsive documents are found is obvious as well. Recall reached 60% upon review of just 179 documents — only slightly more than what was required in the second simulation. And then the Predict efficiency surpassed both previous simulations, achieving 100% recall upon review of only 1,333 documents—28.6% of the collection, and a savings of 71.4% against a linear review.
Fourth Round
We couldn’t stop here. For the next round, we decided to use a random non-responsive document as the starting point. To our surprise, the results were just as good as the earlier rounds. Figure 4 illustrates these results.
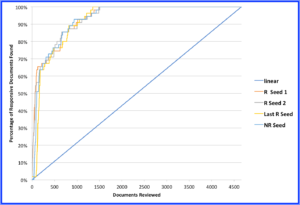
Figure 4
Fifth Round
We decided to make one more simulation run just to see what happened. For this final starting point, we created a synthetic responsive Japanese document. We composited five responsive documents selected at random into a single synthetic seed, started there, and achieved much the same results.[4]
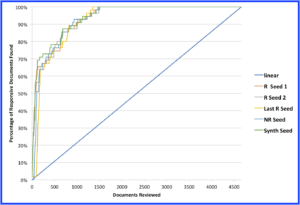
Figure 5
Sixth through 56th Rounds
The consistency of these five results seemed really interesting so for the heck of it we ran simulations using every single responsive document in the collection as a starting point. So, although it wasn’t our plan at the outset, we ultimately simulated 57 Predict reviews across the collection, each from a different starting point (all 55 relevant documents, one non-relevant document, and one synthetic seed).
You can see for yourself from Figure 6 that the results from every simulated starting point were, for the most part, pretty consistent. Regardless of the starting point, once Predict was able to locate a pocket of responsive documents, the gain curve jumped almost straight up until about 60% of the responsive documents had been located.
Gordon Cormack once analogized this ability of a continuous active learning tool to a bloodhound—all you need to do is give Predict the “scent” of a responsive document, and it tracks them down. And in every case, Predict was able to find every one of the responsive documents without having to review even one-third of the collection.
Here is a graph showing the results for all of our simulations:
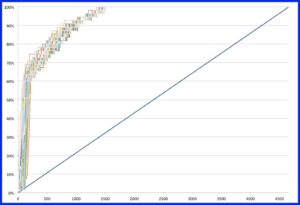
Figure 6
And here are the specifics of each simulation at recall levels of 60%, 80% and 100% recall.
| DocID | Percentage of Collection Reviewed to Achieve Recall Levels | ||
| 60% | 80% | 100% | |
| 27096 | 4% | 15% | 29% |
| 34000 | 2% | 11% | 32% |
| 35004 | 4% | 12% | 32% |
| 83204 | 3% | 11% | 32% |
| 86395 | 4% | 14% | 32% |
| 93664 | 2% | 13% | 32% |
| 98263 | 3% | 11% | 29% |
| 98391 | 2% | 13% | 32% |
| 98945 | 3% | 11% | 32% |
| 99708 | 4% | 12% | 32% |
| 99773 | 2% | 10% | 32% |
| 99812 | 2% | 11% | 32% |
| 99883 | 2% | 12% | 32% |
| 99918 | 5% | 14% | 32% |
| 100443 | 4% | 12% | 32% |
| 100876 | 3% | 13% | 32% |
| 101211 | 4% | 12% | 32% |
| 101705 | 3% | 14% | 31% |
| 101829 | 3% | 11% | 31% |
| 102395 | 3% | 13% | 32% |
| 102432 | 4% | 14% | 32% |
| 102499 | 2% | 9% | 32% |
| 102705 | 3% | 14% | 32% |
| 103803 | 4% | 12% | 32% |
| 105017 | 2% | 14% | 32% |
| 105799 | 3% | 13% | 32% |
| 106993 | 2% | 12% | 30% |
| 107315 | 2% | 14% | 32% |
| 109883 | 4% | 12% | 32% |
| 110350 | 3% | 15% | 30% |
| 112905 | 4% | 14% | 32% |
| 117037 | 4% | 12% | 32% |
| 118353 | 4% | 14% | 32% |
| 119216 | 4% | 15% | 32% |
| 119258 | 2% | 12% | 32% |
| 119362 | 2% | 10% | 32% |
| 121859 | 3% | 11% | 32% |
| 122000 | 4% | 15% | 29% |
| 122380 | 5% | 11% | 30% |
| 123626 | 3% | 10% | 32% |
| 123887 | 3% | 11% | 32% |
| 124517 | 3% | 14% | 32% |
| 125901 | 3% | 14% | 32% |
| 130558 | 2% | 14% | 32% |
| 131255 | 4% | 10% | 32% |
| 132604 | 2% | 10% | 32% |
| 136819 | 3% | 14% | 29% |
| 140265 | 4% | 13% | 32% |
| 140543 | 4% | 12% | 32% |
| 147820 | 3% | 14% | 32% |
| 154413 | 4% | 13% | 32% |
| 238202 | 4% | 12% | 32% |
| 242068 | 4% | 12% | 32% |
| 245309 | 4% | 16% | 32% |
| 248571 | 4% | 12% | 32% |
| NR | 3% | 14% | 32% |
| SS | 2% | 13% | 31% |
| Min | 2% | 9% | 29% |
| Max | 5% | 16% | 32% |
| Avg | 3% | 13% | 32% |
Table 1
As you can see, the overall results mirrored our earlier experiments, which makes a powerful statement about the ease of using a CAL process. Special search techniques and different training starts seemed to make very little difference in these experiments. We saw this through our TREC 2016 experiments as well. We tested different, and minimalist, methods of starting the seeding process (e.g. one quick search, limited searching), and found little difference in the results. See our report and study here.
What did we learn from the simulations?
One of the primary benefits of a simulation as opposed to running CAL on a live matter is that you can pretty much vary and control every aspect of your review to see how the system and results change when the parameters of the review change. In this case, we varied the starting point, but kept every other aspect of the simulated review constant. That way, we could compare multiple simulations against each other and determine where there may be differences, and whether one approach is better than any other.
The important takeaway is the fact that the review order of these various experiments is exactly the same review order that the client would achieve, had they reviewed these documents in Predict, at a standard review rate of about one document per minute, and made the exact same responsiveness decisions on the same documents.
Averaged across all the experiments we did, Predict was able to find just over half of all responsive documents (50% recall) after reviewing only 89 documents (1.9% of the collection; 98.1% savings). Predict achieved 75% recall after reviewing only 534 documents (11.5% of the collection; 88.5% savings). And finally, Predict achieved an otherwise unheard of complete 100% recall on this collection after reviewing only 1,450 documents (31.1% of the collection; 68.9% savings).
Furthermore, Predict is robust to differences in initial starting conditions. Some starting conditions are slightly better than others. In one case, we achieved 50% recall after only 65 documents (1.4% of the collection; 98.6% savings) whereas in another it took 163 documents to reach 50% recall (3.5% of the collection; 96.5% savings). However, the latter example achieved 100% recall after only 1,352 documents (29% of the collection; 71% savings), whereas the earlier example achieved 100% recall after 1,507 documents (32.3% of the collection; 67.7% savings).
Overall, the key is not to focus on minute differences, because all these results are within a relatively narrow performance range and follow the same general trend.
Other key takeaways:
- Predict’s implementation of CAL works extremely well on low richness collections. Starting with only 55 relevant documents out of nearly 5,000 typically makes finding the next relevant document difficult, but Predict excelled with a low richness collection.
- This case involved OCR’d documents. Some people have suggested that TAR might not work well with OCR’d text but that has not been our experience. Predict worked well with this population.
- All documents were in Japanese. We have written about our success in ranking non-English documents but some have expressed doubt. This study again illustrates the effectiveness of Predict’s analytical tools when the documents are properly tokenized.
These experiments show that there are real, significant savings to using Predict, no matter the size, richness or language of the document collection.
Conclusion
Paul Simon, that great legal technologist, knew long ago that it was time to put an end to keywords and linear review:
The problem is all inside your head, she said to me.
The answer is easy if you take it logically.
I’d like to help you as we become keyword free.
There must be fifty-seven ways to leave your (linear) lover.
She said it’s really not my habit to intrude.
But this wasteful spending means your clients are getting screwed.
So I repeat myself, at the risk of being cruel.
There must be fifty-seven ways to leave your linear lover,
Fifty-seven ways to leave your (linear) lover.
Just slip out the back, Peck, make a new plan, Ralph.
Don’t need to be coy, Gord, just listen to me.
Hop on the bus, Craig, don’t need to discuss much.
Just drop the keywords, Mary, and get yourself (linear) free.
She said it grieves me so to see you in such pain.
When you drop those keywords I know you’ll smile again.
I said, linear review is as expensive as can be.
There must be fifty-seven ways ways to leave your (linear) lover.
Just slip out the back, Shira, make a new plan, Gord.
Don’t need to be coy, Joy, just listen to me.
Hop on the bus, Tom, don’t need to discuss much.
Just drop the keywords, Gayle, and get yourself (linear) free.
She said, why don’t we both just sleep on it tonight.
And I believe, in the morning you’ll begin to see the light.
When the review team sent their bill I realized she probably was right.
There must be fifty-seven ways to leave your (linear) lover.
Fifty-seven ways to leave your (linear) lover.
Just slip out the back, Maura, make a new plan, Fatch.
Don’t need to be coy, Andrew, just listen to me.
Hop on the bus, Michael, don’t need to discuss much.
Just drop off the keywords, Herb, and get yourself (linear) free.
[1] We chose to initiate the ranking using a single document simply to see how well Predict would perform in this investigation from the absolute minimum starting point. In reality, a Predict simulation can use as many responsive and non-responsive documents as desired. In most cases, we use the same starting point (i.e., the exact same documents and judgments) used by the client to initiate the original review that is being simulated.
[2] We chose to review twenty documents at a time because that is what we typically recommend for batch sizes in an investigation, to take maximum advantage of the ability of Predict to re-rank several times an hour.
[3] It is interesting to note that Predict did not find relevant documents as quickly using a non-relevant starting seed, which isn’t surprising. However, it caught up with the earlier simulation by the 70% mark and proved just as effective.
[4] Compositing the text of five responsive documents into one is a reasonable experiment to run. But it’s not what most people think of when they think synthetic seed. They imagine some lawyer crafting verbiage him- or herself, writing something up about what they expect to find, in their own words. And then using that document to start the training. Using the literal text of five documents already deemed to be responsive is not the same thing but it made for an interesting experiment.
Prior to forming Catalyst, John was a nationally known trial lawyer and longtime litigation partner at Holland & Hart. Over the past four decades he has written or edited eight books and countless articles on legal technology topics, including two American Bar Association best sellers on using computers in litigation technology, a book (supplemented annually) on deposition techniques and several other widely-read books on legal analytics and technology. He served as Chair of the ABA’s Law Practice Section and edited its flagship magazine for six years.
John’s legal and technology acumen has earned him numerous awards including being named by the American Lawyer as one of the top six “E-Discovery Trailblazers,” named to the FastCase 50 as a legal visionary and named him one of the “Top 100 Global Technology Leaders” by London Citytech magazine. He has also been named the Ernst & Young Entrepreneur of the Year for Technology in the Rocky Mountain Region, and Top Technology Entrepreneur by the Colorado Software and Internet Association. John regularly speaks on legal technology to audiences across the globe. In his spare time, you will find him competing on the national equestrian show jumping circuit or playing drums and singing in a classic rock jam band.