
Within the field of Natural Language Processing (NLP) there are a number of techniques that can be deployed for the purpose of information retrieval and understanding the relationships between documents. The growth in unstructured data requires better methods for legal teams to cut through and understand these relationships as efficiently as possible. The simplest way of finding similar documents is by using vector representation of text and cosine similarity. One method for concept searching and determining semantics between phrases is Latent Semantic Indexing/Latent Semantic Analysis (LSI/LSA).
LSI/LSA is an application of Singular Value Decomposition Technique (SVD) on the word-document matrix used in Information Retrieval. LSA is a NLP method that analyzes relationships between a set a documents and the terms contained within. The primary use is concept searching and automated document categorization. However, it has also found use in software engineering (to understand source code), publishing (text summarization), search engine optimization, and other applications.
LSA and LSI are closely related. LSI came first and was deployed in the area of information retrieval, whereas LSA came slightly later and was used more for semantic understanding and also exploring various cognitive models of human lexical acquisition. LSI was proposed in 1990 by a team of researchers as a text searching technique. The most prominent researcher in the team was Susan Dumais, who currently works a distinguished scientist at Microsoft Research. LSA was later proposed in 2005 by Jerome Bellegarda specifically for NLP tasks. Bellegarda showed massive improvements in speech recognition tasks due to the ability of the LSA to capture long-term (or semantic) context of text.
In my view the difference between LSI and LSA is slight – while LSI builds a term by document matrix, LSA has often relied on term by article matrices (hoping to better capture the semantics of words and phrases). They are near synonyms where the difference depends on your application (IR or lexical semantics) or perhaps your orientation (retrieval tool versus cognitive model).
The Process
To extract and understand patterns from documents, LSA inherently follows certain assumptions:
- Meaning of Sentences or Documents is a sum of the meaning of all words occurring in it. Overall, the meaning of a certain word is an average across all the documents it occurs in.
- LSA assumes that the semantic associations between words are present not explicitly, but only latently in the large sample of language.
LSA comprises certain mathematical operations to gain insight on a document. This algorithm forms the basis of Topic Modeling. The core idea is to take a matrix of what we have – documents and terms – and decompose it into a separate document topic matrix and a topic-term matrix. . A typical example of the weighting of the elements of the matrix is tf-idf (term frequency – inverse document frequency): the weight of an element of the matrix is proportional to the number of times the terms appear in each document, where rare terms are upweighted to reflect their relative importance. It can also be constructed using a Bag-of-Words Model, but results are sparse and do not provide any significance to the matter.
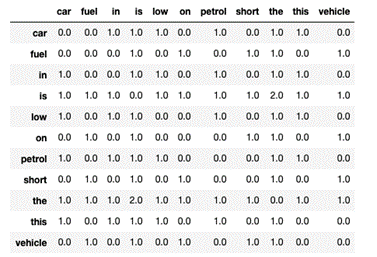
To reduce the computation complexity of the document-term matrix and get more relevant and useful results Singular Value Decomposition (SVD) is used. SVD is a technique in linear algebra that factorizes any matrix M into the product of 3 separate matrices: M=U*S*V, where S is a diagonal matrix of the singular values of M. The main advantage of SVD is that we can reduce the size of the matrix substantially from millions to hundreds. With these document and term vectors, we can now easily apply measures such as cosine similarity to evaluate the similarity of different documents, the similarity of different words, and the similarity of terms (or “queries”) and documents (which becomes useful in information retrieval, when we want to retrieve passages most relevant to our search query).
Two of the problems (among many) that LSI sets out to solve are the issues of synonymy and polysemy:
- Synonymy is the phenomenon where different words describe the same idea. Thus, a query in a search engine may fail to retrieve a relevant document that does not contain the words which appeared in the query. For example, a search for “doctors” may not return a document containing the word “physicians”, even though the words have the same meaning.
- Polysemy is the phenomenon where the same word has multiple meanings. So a search may retrieve irrelevant documents containing the desired words in the wrong meaning. For example, a botanist and a computer scientist looking for the word “tree” probably desire different sets of documents.
LSI helps overcome synonymy by increasing recall, one of the most problematic constraints of Boolean keyword search queries and vector space models. Synonymy is often the cause of mismatches in the vocabulary used by the authors of documents and the users of information retrieval systems. As a result, Boolean or keyword queries often return irrelevant results and miss information that is relevant.
A number of experiments have demonstrated that there are several correlations between the way LSI and humans process and categorize text. The inspiration behind these experiments originated from both engineering and scientific perspectives, where researchers from New Mexico State University considered the design of learning machines that can acquire human-like quantities of human-like knowledge from the same sources. This is because traditionally, imbuing machines with human-like knowledge relied primarily on the coding of symbolic facts into computer data structures and algorithms. A critical limitation of this approach was that it failed to address the unconscious human ability to source vast amounts of data collected over the course of a human’s life. This also fails to address important questions about how humans acquire and represent this data in the first place.
The Future
In the context of quantum computing and quantum information retrieval, latent topic analysis (LTA) is a valuable technique for document analysis and representation. To refresh: the promise of quantum computers is that certain computational tasks might be executed exponentially faster on a quantum processor than on a classical processor. Today’s computers operate in a very straightforward fashion: they manipulate a limited set of data with an algorithm and give you an answer. Quantum computers are more complicated. After multiple units of data are input into qubits, the qubits are manipulated to interact with other qubits, allowing for several calculations to be done simultaneously.
Quantum information retrieval has the remarkable virtue of combining both geometry and probability in a common principled framework. The quantum-motivated representation is an alternative for geometrical latent topic modeling worthy of further exploration. The approaches followed by both QLSA and LSA are very similar, the main difference is the document representation used. LTA methods based on probabilistic modeling, such as PLSA and LDA, have shown better performance than geometry-based methods. However, with methods such as QLSA it is possible to bring the geometrical and the probabilistic approaches together.
