
In late February 2019 the AI world enjoyed a viral moment when a machine learning framework was used to create a website called “this person does not exist”. Created using generative adversarial networks (GANs) made open source by Nvidia, the website generates an invented, photo-realistic image of human being with each refresh. The key word in that sentence is invented.
GANs provide a way to learn deep representations without extensively annotated training data. They achieve this by deriving backpropagation signals through a competitive process involving a pair of networks. The representations that can be learned by GANs may be used in a variety of applications, including image synthesis, semantic image editing, style transfer, image superresolution, and classification.
The website itself is spooky, and if it isn’t then please keep hitting that refresh button. These. People. Do. Not. Exist. Once the wow-factor has evaporated and the page begins to feel eerily unsettling, ask yourself: “what are some of the problems this technology could produce?”. Consider the constant battle against cyber criminals using all variety of tools to con unsuspecting individuals into divulging sensitive information. It is hard enough to teach digitally active senior citizens about the dangers of email links designed to socially engineer interaction. How do you prepare your family and colleagues in an age when individuals and organizations rampantly use stock images and stolen social media photos to hide their identities while they manipulate and scam others? These cons range from to pet scams to romance scams to fake news proliferation to many others. Giving scammers a source of infinite, untraceable, and convincing fake photos to use for their schemes is like releasing a gun to market that does not imprint DNA.
Discriminative vs Generative Modeling
In supervised learning, we may be interested in developing a model to predict a class label given an example of input variables. This predictive modeling task is called classification. Classification is also traditional referred to as discriminative modeling:
A model must discriminate examples of input variables across classes; it must choose or decide as to what class a given example belongs.
Alternatively, unsupervised models that summarize the distribution of input variables may be able to be used to create or generate new examples in the input distribution. As such, these types of models are referred to as generative models:
Approaches that explicitly or implicitly model the distribution of inputs as well as outputs are known as generative models, because by sampling from them it is possible to generate synthetic data points in the input space.
Generative Adversarial Networks
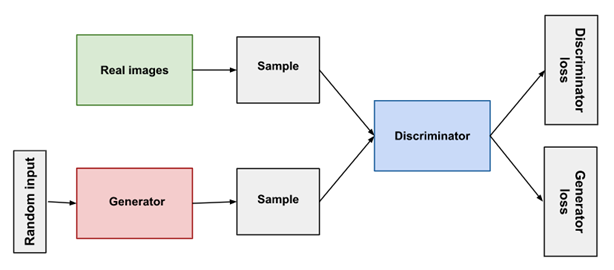
GANs are a deep-learning-based generative model. More generally, GANs are a model architecture for training a generative model, and it is most common to use deep learning models in this architecture. Highlighted above, the GAN model architecture involved two sub-models: a generative model for generating new examples, and a discriminator model for classifying whether generated examples are real, from the domain, or fake, generated by the generator model. GANs are based on a game theoretic scenario in which the generator network must compete against an adversary. The generator network directly produces examples. Its adversary, the discriminator network, attempts to distinguish between samples drawn from the training data and samples drawn from the generator.
The Generator Model
The generator model takes a fixed-length random vendor as input and generates a sample in the domain. The vector is drawn randomly from a Gaussian distribution, and the vector is used to seed the generative process. After training, points in the problem domain, forming a compressed representation of the data distribution. This vector space is referred to as a latent space, or a vector space comprised of latent variables. Latent variables, or hidden variables, and those variables that are important for domain but are not directly observable. In the case of GANs, the generator model applies meaning to points in a chosen latent space, such that new points drawn from the latent space can be provided to the generator model as input and used to generate new and different output examples.
The Discriminator Model
The discriminator model takes an example for the domain (real or generated) and predicts a binary class label of real or fake (generated). The real example comes from the training dataset. The generated examples are output by the generator model. The discriminator is the normal (and well understood) classification model. After the training process, the discriminator model is discarded as we are interested in the generator. Sometimes, the generator can be repurposed as it has learned to effectively extract features from examples in the problem domain.
The Process
When training begins, the generator produces obviously fake data, and the discriminator quickly learns to tell that it’s fake:

As training progresses, the generator gets closer to producing output that can fool the discriminator:

Finally, if generator training goes well, the discriminator gets worse at telling the difference between real and fake. It starts to classify fake data as real, and its accuracy decreases.

Here is a diagram of the whole system:
Before this technology came to light, individuals motivated to scam unsuspecting victims faced three major risks when using fake photos. The first risk (and most unlikely) was that someone would recognize the photo and identify the activity as suspicious. The second would involve someone reverse image searching the photo in question with readily available services like TinEye or Google Image Search. Reverse image search is one of the top anti-fraud measures recommended by consumer protection advocates. Finally, If the crime is successful, law enforcement uses the fake photo to figure out the scammer’s identity after the fact.
AI-generated images carry none of these risks. Simply put, no one will recognize a human who has never existed before. Google image search will return no results and law enforcement won’t have a great deal of use for the data in question. Beyond this, GANs provide another advantage for cyber criminals: scale. There is difficulty in creating large numbers of fake profiles without getting sloppy and leaving subtle tells. But if you can automatically generate realistic profiles in an instant, you’ve just opened the pandoras box of social engineering.
The challenges here are broad. Better AI is needed in order to proactively monitor and combat these risks; however, the creativity of scammers often trumps the efforts of risk-identification efforts that incorporate large scale sophisticated machine learning applications. There are several reasons for this gap, but significant work needs to be done in the realms of change management and AI education if governments, individuals, and public and private businesses are going to meet this challenge with robust solutions. If people do not understand or trust AI, they are unlikely to maximize its potential.
The real trouble with cyber criminals leveraging advanced machine learning frameworks like GANs is the knee-jerk reaction that has become increasingly more common in our society. Conspiracy groups have sowed distrust in everything from vaccinations and electoral results to the very shape of the earth. I find it difficult to believe that they would see reason in participating and trusting in public or private efforts to educate the public and grow participation in solutions that leverage one type of AI to protect against a different form of AI. To much of the public, the mention of AI still translates to science fiction and the dooms-day scenario famously depicted in Terminator. Educating against this level of cyber-criminal activity cannot begin early enough, and given our current public discourse, there is a lot to be done if we are hoping to succeed.
