
March 4, 2023 – Searching for Emojis in Relativity
A Relativity admin can make it possible to search for emojis in a Relativity workspace. A dtSearch index can be edited to include a special code that will enable the ability to search for a range of different emojis.
An existing dtSearch index can be edited. On the Alphabet tab, in the section marked ‘[End]’ the following code can be entered:
TokenCharRanges32 = 1f000-1f0ff 1f300-1f6ff 1f700-1f77f 1f900-1f9ff
After the index is saved, it will be necessary to build the full index. Click on the option on the console to the right.
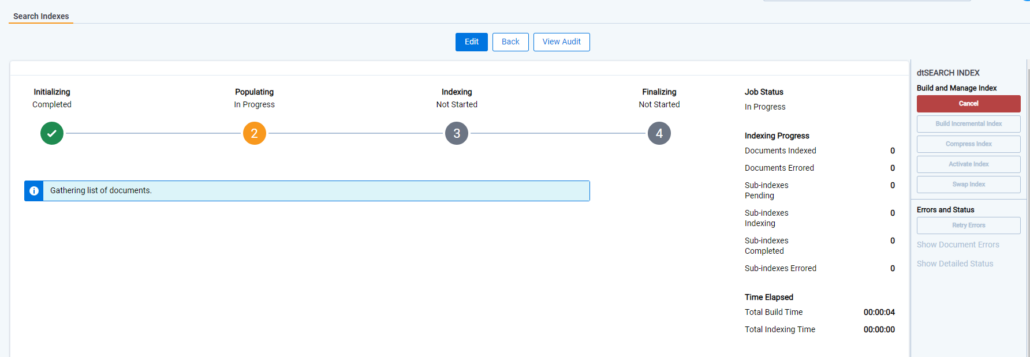
The process may take some time.
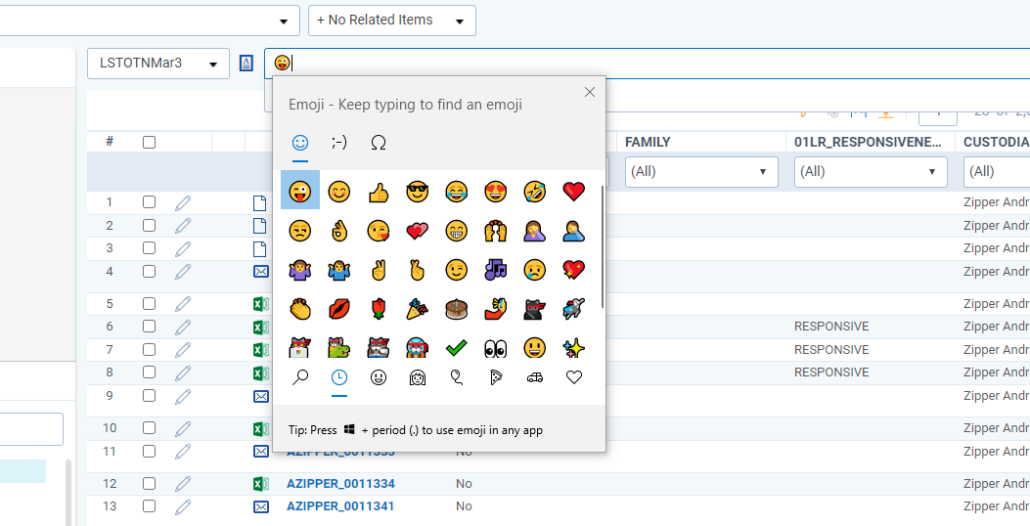
When the index is rebuilt, it will be possible to enter the image of an emoji and then locate it the extracted text of any document in the search results. Press the Windows key + period to bring up an emoji chart.
March 12, 2023 – Powershell Script to Add Text to a File
You can easily add text to the end of a text file using the PowerShell Add-Content command. So if you have text file like this which has only one line of text:
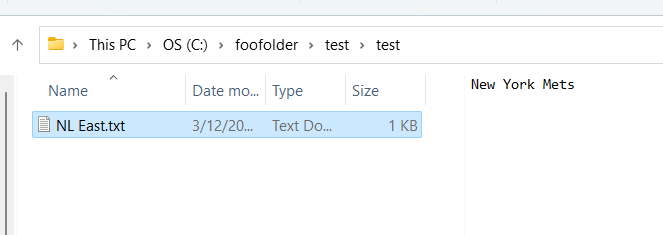
. . .and you want to add four new lines of text, you can write a PowerShell script like this:
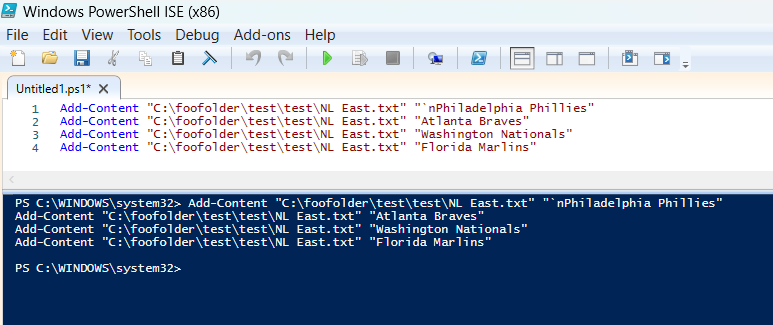
Add-Content “C:\foofolder\test\test\NL East.txt” “`nPhiladelphia Phillies”
Add-Content “C:\foofolder\test\test\NL East.txt” “Atlanta Braves”
Add-Content “C:\foofolder\test\test\NL East.txt” “Washington Nationals”
Add-Content “C:\foofolder\test\test\NL East.txt” “Florida Marlins”
Open Windows PowerShell ISE [everyone running Windows should have this preinstalled], and enter the script in the script pane, and then run the script by clicking the green play button.
Note that for the first new line, we need to indicate that a line break should be entered. This is done by using a backtick ‘`’ and an ‘n’ as a reference. The backtick is not the same as an apostrophe. On most keyboards it will be at the top far left before the number keys, and below the tilde key. Adding a `n reference for each new line will lead to the new entries being double spaced.
March 17, 2023 – Is Robocopy the Fastest Way to Transfer Files?
The Tip of the Night for December 24, 2022 noted that using a PowerShell script to copy multiple files from multiple locations to another location will work faster than XCOPY.
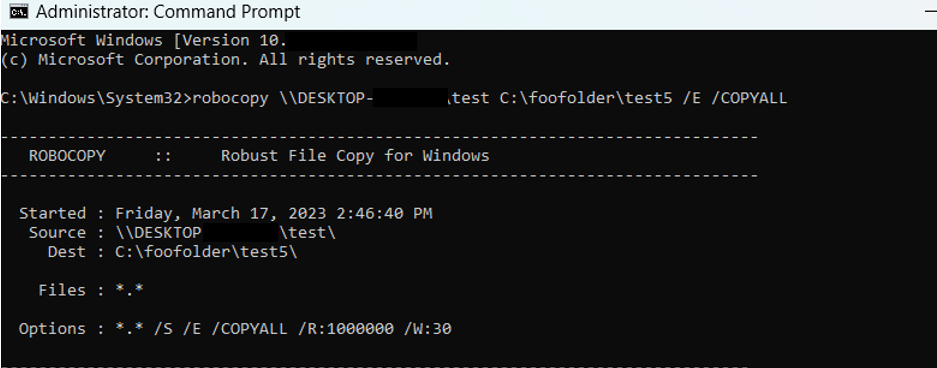
There is some debate online about whether or not the robocopy command will be faster than Windows Explorer copying the contents of one directory to another folder. I decided to test Explorer, robocopy, xcopy, and PowerShell against one another to see if there was any real difference when copying a single data set to a new location.
A took a sample of1824 files in 17 folders which came to 7.13 GB, and ran commands to transfer them from an external solid state drive to the C drive of a Dell XPS laptop with 16 GB of RAM. There was little difference in the elapsed time for each method, so the thing to do is to keep it simple and use Explorer. I guess the jury is out as to whether robocopy would work faster on a network. I will try to test this soon . . .
Windows Explorer 1 minute 9 seconds
robocopy 1 minute 14 seconds
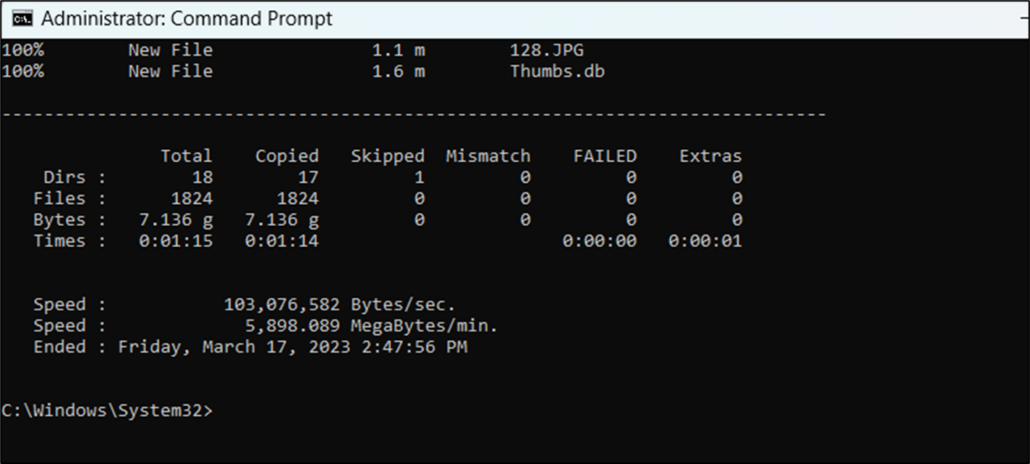
PowerShell 1 minute 14 seconds
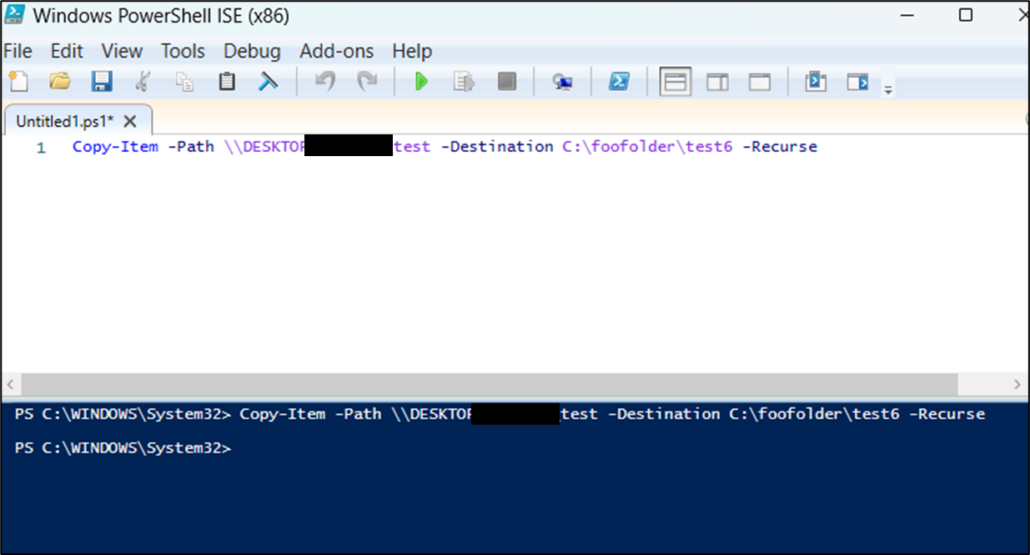
xcopy 1 minute 14 seconds
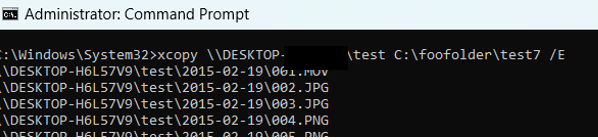
Note that when using robocopy it’s necessary to share the source folder, and run the command in the admin mode of command prompt.
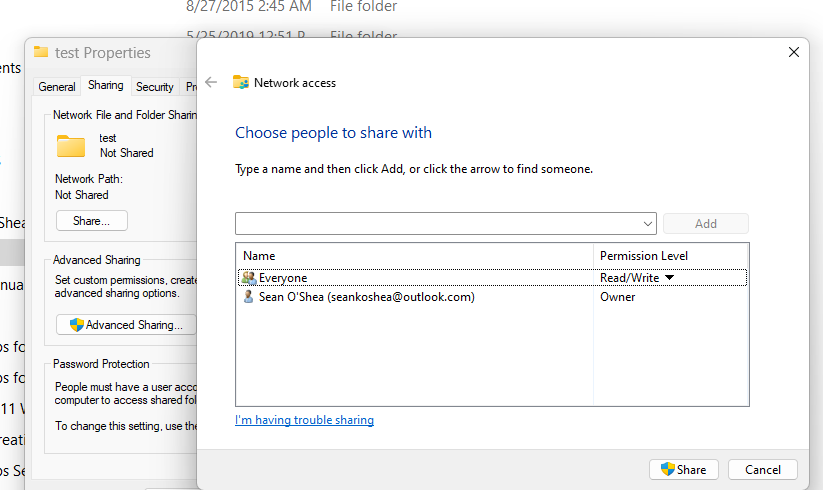
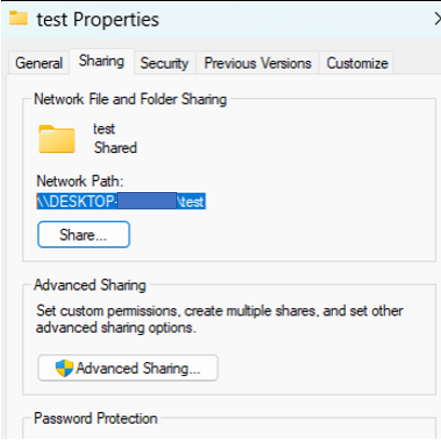
When setting the location for an external hard drive used as a source, copy the network path located under Properties. The device itself should have an alphanumeric code something like H4L34V8 – the code for my drive has been redacted in these screen grabs.
March 24, 2023 – Beware of Dropped Decimal Places in Excel
When working with data from .csv files in Excel that includes numbers with multiple decimal places, take special care to make sure none of the decimal places are cut off.
If you have an Excel spreadsheet with differing decimal places in a column of numbers, and the column is not formatted to display all of the decimal numbers:
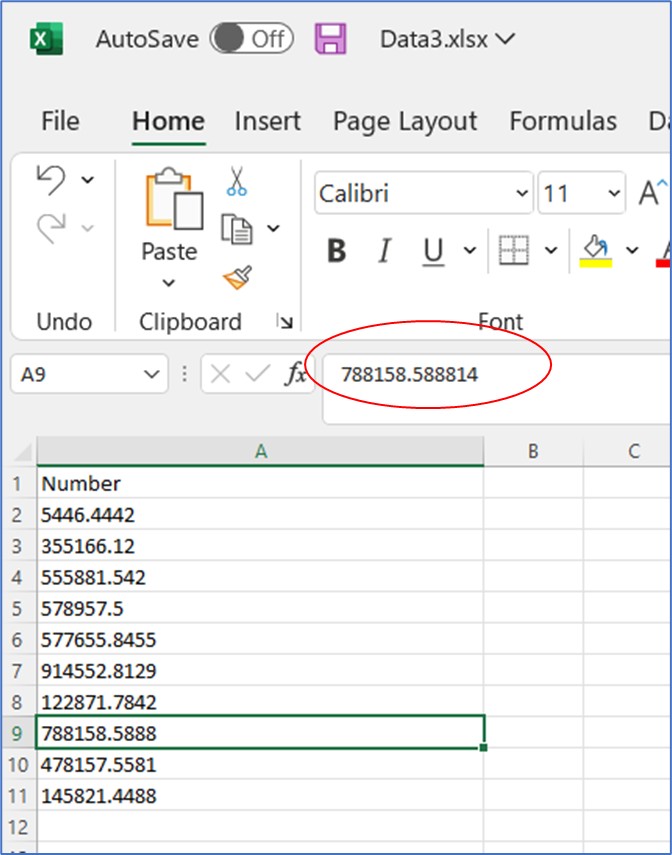
. . . when the file is saved to a .csv file, the undisplayed decimals will be dropped.
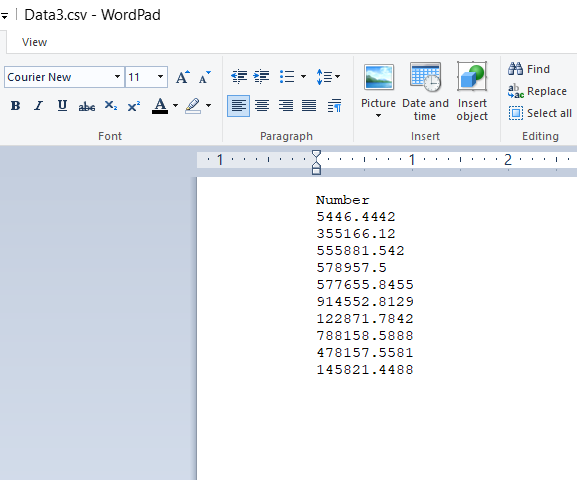
If you have an existing .csv file which has numbers with varying numbers of decimal places, which is opened, edited, and saved in Excel:
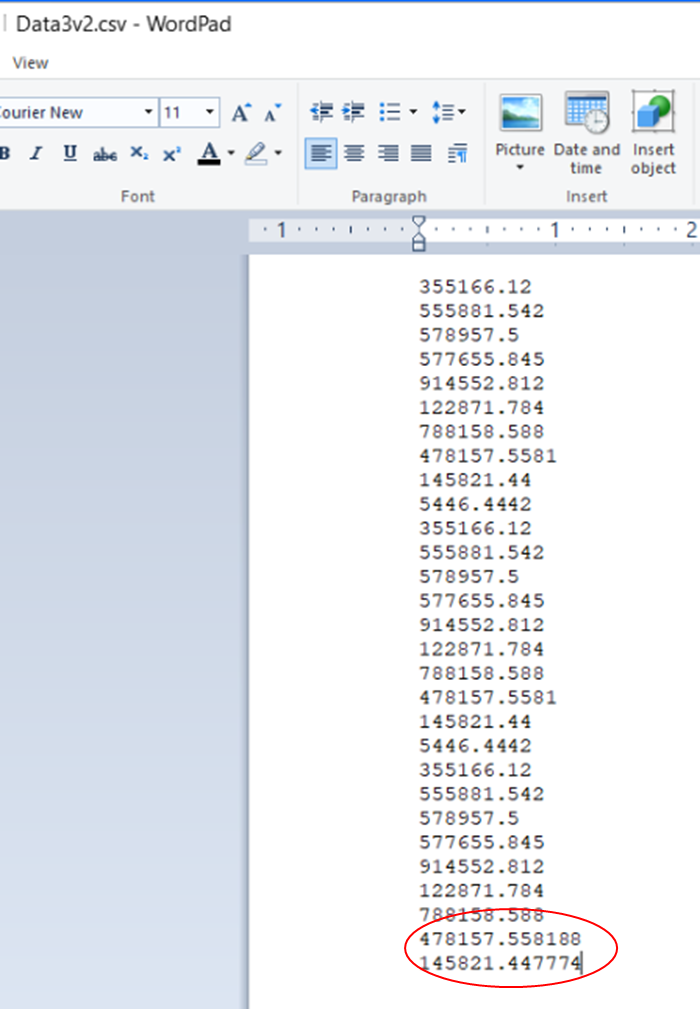
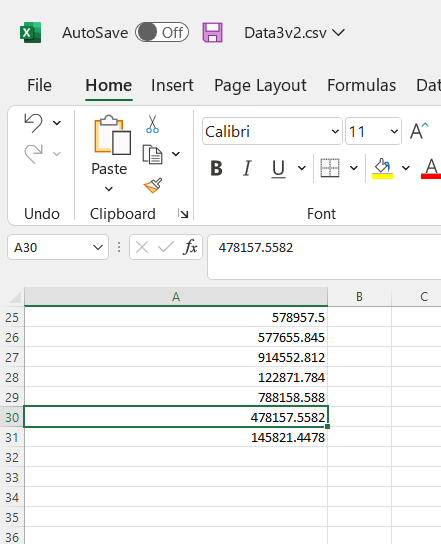
. . . some of the decimal places may be dropped when the file is opened in Excel again, and the numbers rounded up:
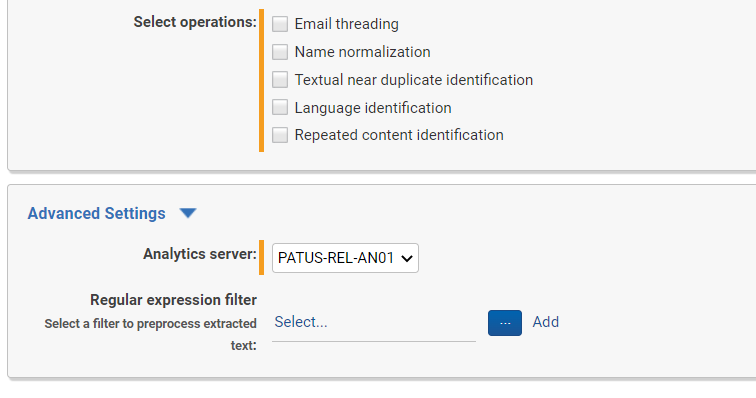
March 31, 2023 – Set Regex Filters in Relativity Structured Analytics Sets for Pipeline Text
Keep in mind that when you set a regular expression filter for a structured analytics set in Relativity, the regex filter will not be run against the extracted text as you can see it for a document in the Viewer. While the extracted text is displayed with line breaks and whitespace, this text is transformed when it is in the Analytics pipeline. The pipeline text uses the regex \r\n markers [return and newline] in place of line breaks, and will consolidate multiple blank spaces to a single space.
Extracted text may look like this:
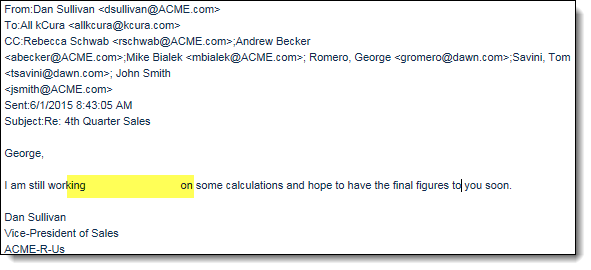
. . . but the pipeline text will look like this:

There’s just one long string of text in the analytics pipeline. So if you want to search for an email footer reading, “Under the General Data Protection Regulation GDPR 2016 679 we have a legal duty to protect any information we collect from you”, accounting for varying GDPR sections, a regex filter for a structured analytics set . . .
. . . should be set like this:
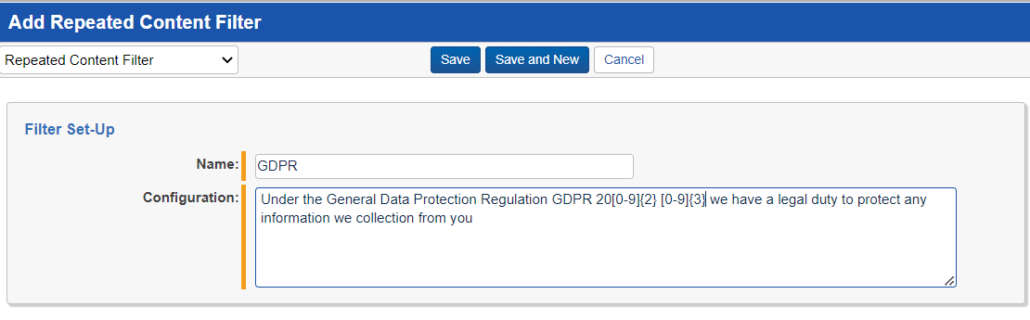
. . . without the additional spaces before and after the relevant GDPR section.
If you want to filter out multiple disclaimers added to email footers, and Bates numbers from more than one party’s production, you’ll need to craft a single regex search which can account for all these targeted terms. No more than one regex filter can be applied to a structured analytics set.

*The views expressed in this blog are those of the owner and do not reflect the views or opinions of the owner’s employer. All content provided on this blog is for informational purposes only. The owner of this blog makes no representations as to the accuracy or completeness of any information on this site or found by following any link on this site. The owner will not be liable for any errors or omissions in this information nor for the availability of this information. The owner will not be liable for any losses, injuries, or damages from the display or use of this information. This policy is subject to change at any time. The owner is not an attorney, and nothing posted on this site should be construed as legal advice. Litigation Support Tip of the Night does not provide confirmation that any e-discovery technique or conduct is compliant with legal, regulatory, contractual or ethical requirements.