
What do you say if somebody asks you what the algorithm is doing with your data? How does it learn? What is it looking at and why? Defensible use of AI is important, whether during litigation or through some other application such as monitoring for various forms of risk. Achieving a collective understanding of how the technology you are using works will become significantly more important as these tools become ubiquitous with legal data. In artificial intelligence there are several ways to skin a cat. Given the growing complexity of data in both type and size, it is important for legal teams to understand a little bit more about the algorithms themselves.
Before we jump into any complexity, let us review some baseline concepts. Supervised learning is a form of machine learning commonly used in predictive coding. LegalTech vendors focused on building AI solutions have made impressive use of supervised learning techniques in the pursuit of more speed to insight during document review. In supervised learning, we are interested in developing a model to predict a class label given an example of input variables. This predictive modeling task is called classification. Classification is also traditionally referred to as discriminative modeling.
A model must discriminate examples of input variables across classes; it must choose or decide as to what class a given example belongs. This is what happens during a supervised predictive coding process when a review attorney codes documents for relevance. However, in order to understand exactly how the data is modeled, it’s important to dig a little deeper and familiarize ourselves with the underlying algorithms most commonly used to achieve these goals. Today, we are going to review one commonly used algorithm: support vector machines.
Many LegalTech firms with AI based predictive coding functions utilize SVMs because they are one of the most robust prediction methods. This is due to their foundation in statistical learning frameworks. SVMs are consistently the go-to method for a high-performing algorithm with little tuning. This means less work is required in the creation of a reliable AI model. SVMs are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis. Like many classification and prediction methods, SVMs classify binary outcomes (e.g., reviewing documents as responsive versus nonresponsive) by estimating a separation boundary within the space defined by a set of predictor variables. A given observation, defined by the values of the predictor variables is classified based on which side of the boundary it falls.
The objective of SVMs is to find a hyperplane in an N-dimensional space (N – number of features of the data) that distinctly classifies the data points. In the context of litigation and document review, features within the data could be represented by any number of factors including metadata, emotional signals, and relevant entities such as the names people, places, organizations, or things. Support vectors are the data points that lie closest to the decision surface (or hyperplane). They are the data points most difficult to classify and have a direct bearing on the optimum location of the decision surface. Hyperplanes are decision boundaries that help classify the data points. Data points falling on either side of the hyperplane can be attributed to different classes.
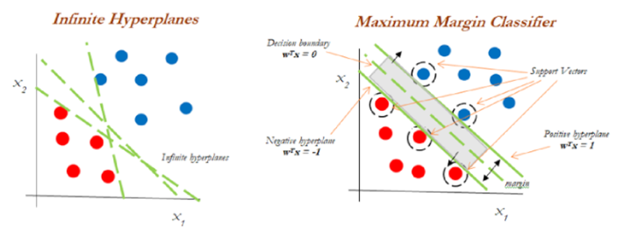
To separate the two classes of data points, there are many possible hyperplanes that could be chosen. Our objective is to find a plane that has the maximum margin, i.e the maximum distance between data points of both classes. SVMs maximize the margin around the separating hyperplane, with the decision function fully specified by a very small subset of training samples (the support vectors). Maximizing the margin distance provides some reinforcement so that future data points can be classified with more confidence. This makes SVMs a highly preferred algorithm for data scientists because it produces significant accuracy with less computation power.
We can go into more detail, but there is little need to go into greater depth for the average eDiscovery professional. The important part is understanding the problem of supervised learning and the most utilized algorithms, like SVMs. Remember that in supervised learning we may be interested in developing a model to predict (classify) a class label (data point) given an example of input variables (training data). The model must discriminate examples of input variables across classes; it must choose or decide as to what class a given example belongs. When review attorneys are facing a discovery process involving several terabytes of data, it helps to understand exactly how the algorithm is looking at your data. Remember, what if someone asks you to explain which algorithm you have used and what the algorithm is doing? Best be prepared.
